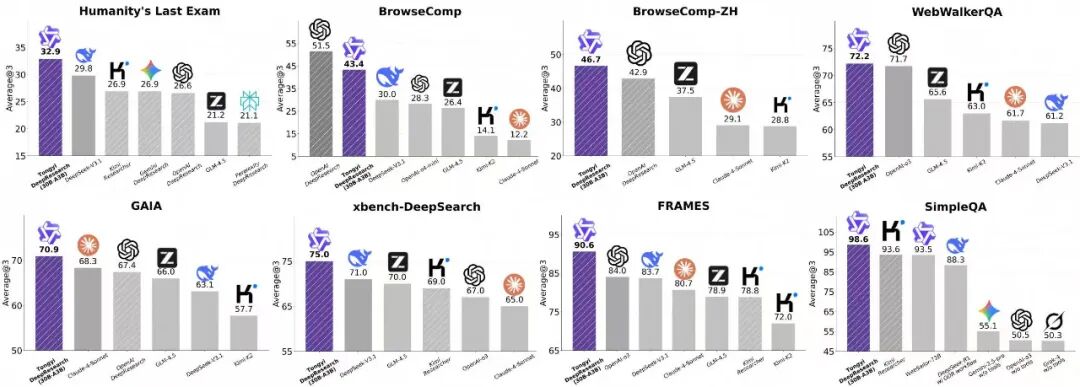
相比于海外的旗舰模型昂贵和限制的调用,通义 DeepResearch 团队做到了完全开源!开源模型,开源框架,开源方案!在 Humanity’s Last Exam、BrowseComp、BrowseComp-ZH、GAIA、xbench-DeepSearch, WebWalkerQA 以及 FRAMES 等多个 Benchmark 上,相比于基于基础模型的 ReAct Agent 和闭源 Deep Research Agent,其 30B-A3B 轻量级 tongyi DeepResearch,达到了 SOTA 效果。
通义 DeepResearch 团队也在 Blog 和 Github 完整分享了一套可落地的 DeepResearch Agent 构建方法论,系统性地覆盖了从数据合成、Agentic 增量预训练 (CPT)、有监督微调 (SFT) 冷启动,到强化学习 (RL) 的端到端全流程。尤其在 RL 阶段,该团队提供了集算法创新、自动化数据构建与高稳定性基础设施于一体的全栈式解决方案。在推理层面,模型展现出双重优势:基础的 ReAct 模式无需提示工程即可充分释放模型固有能力;而深度模式 (test-time scaling) 则进一步探索了其在复杂推理与规划能力上的上限。
- Homepage: https://tongyi-agent.github.io/
- Blog: https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
- Github: https://github.com/Alibaba-NLP/DeepResearch
- Hugging Face: https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B
- Model Scope: https://modelscope.cn/models/iic/Tongyi-DeepResearch-30B-A3B
1 数据策略:基于全合成数据的增量预训练和后训练
模型能力的提升,主要得益于通义 DeepResearch 团队设计的一套多阶段数据策略。这个策略的核心目标是,不依赖昂贵的人工标注,也能大规模地生成高质量的训练数据。
1.1 增量预训练数据
团队引入了 Agentic CPT(增量预训练)来为模型打下坚实的 Agent 基础。为此,开发了一个系统化、可扩展的数据合成方案。它能利用后续训练流程产生的数据,形成一个数据生成的正向循环。
- 数据重组和问题构建 基于广泛收集和增量更新的知识文档、公开可用的爬虫数据、知识图谱以及后训练产生的轨迹数据和工具调用返回结果(例如,搜索结果和网页访问记录)等,团队构建了一个以实体为锚定的开放世界知识记忆。进一步,研究者基于采样的实体和相关知识构造多风格的(问题,答案)对,以尽可能涵盖智能体所面临的真实场景。




